 У
У
���ࣺ��ͬ̽��Χ�弫�ް��� ��AlphaGo�����˰�

- �Ա�ү��С��ñLV.����
- 2017/10/19 22:52:10

����5��27�գ�����ڼ��ڵ�ǰһ�죬�������ֿ½��AlphaGo�Ĺ�������������ˡ�
�����ڹ�ȥ�ļ����AlphaGoսʤ�˵�ʱ�����������ǿ���������֡��½�˵��Ҫרע�ں��������壬���ٺͻ��������ˡ�
����AlphaGo�Ŀ����Ŷ�˵������Ҫרע�ڽ�AlphaGo�ļ���Ӧ�õ���������AlphaGoҲ�����ٺ����������ˡ�
������Ȼ����������꣬������Χ��绹�Ƿ��������������ڲ����ٺ����������̬��ѡ�ֽϾ��ˡ�
����Ȼ����5���º�AlphaGo�������³ɹ�����һ�λ��Ǻ�Χ���йء����˵AlphaGoսʤ�½��ǻ����������ս������ô��һ��AlphaGo Zero��ͻ�Ƹ�����ij�ֿ۹��ɵ�ս����
����AlphaGo�ƺ���������Χ����һ��Ϸ�ľ�ͷ��
������ѧ�ɲŵ�AlphaGo Zero
����AlphaGo�������սʤ������ô��DeepMind����˵������AlphaGo��������������
����û������һ��AlphaGo�Ĵ����ţ�ȷʵ�����ࡰûʲô��ϵ����
����DeepMind��AlphaGo��Ŀ�����Ҫ������David Silver���ܣ�AlpheGo ZeroĿǰ�Ѿ������������������ļ�������֣������������˴�ǰսʤΧ������ھ������h��AlphaGo Lee�汾100�Ρ�
����֮�����������h�İ汾��Ϊ�Աȶ�û��ʹ����½��ս�İ汾���жԱȣ�����Ϊ�ܵ�����������5����������½��ս��AlphaGo��ʵ��һ�����������Alpha Master�汾������һ��TPU�ڲ�����������������ɶ�ս��
���������ǻ��������h�İ汾���ǻ��ܿ½�İ汾����ȥ��AlphaGo�ڡ�ѧϰ������塱����Σ�ʹ�õĶ��Ǵ��������ྭ�����ס����DZ���֪����ĸ����ڲ�ͬ�������Ӧ�����Ӧ�ԡ�����һ�ε�AlphaGo Zero��ѧϰ��������ȫû��ʹ���κ���������ף������淨��̽����ȫ�Ǵ����Ҷ�����ѧϰ�ġ�
������ʼAlphaGo Zero��ӷdz����������ͷ���·���ʼ��������������������һ��AlphaGo Zero����ˮƽҲ�ܵ͡�Ȼ��AlphaGo Zero���ÿһ��ʤ���У�ȡ�þ��飬ʹ���Լ�������ˮƽ������ߡ�
����David Silver˵���ܶ����������˹����ܵ�Ӧ���������������Ǹ���Ҫ�ģ�����AlphaGo Zero��������ʶ�����㷨����Ҫ��Զ�������������ݡ�����AlphaGo Zero�У��Ŷ�Ͷ��������ȴ�����һ���汾��AlphaGo��ʹ����һ����������������
����ʹ���˸��Ƚ����㷨��ԭ������AlphaGo Zero�ij������ܱ����������㣬�����ǵȴ�Ӳ������������������
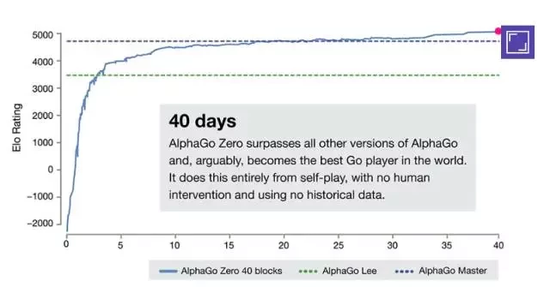
����AlphaGo Zero���㿪ʼ����Χ���������һ����ȫ��������ĺ��ӡ�����ѧϰ3�����AlphaGo Lee��սʤ�����h�汾����21�����AlphaGo Master�������ս60��0�汾������ѵ��40�����˫�������ֺڰ��������£�Zero��Masterʤ�ʳ���90%��
������ѵ����ɵ�AlphaGo Zeroֻ�ܸ������Ƿ�������ѧ�ɲŵ�����Χ�����������ǧ�����ܽ��֪ʶ�Dz�ı���ϵģ������١����ӡ����Ρ������ڶԽǵȣ���������Χ���Ӱ�ӡ�
����������������Ҳ�������ģ���ǡǡ֤�������ڹ�ȥ�ļ�ǧ������������Χ����һ��Ϸ�ġ���Ȼ���ɡ������˹��������������ֵĶԱȾ������������ܲ���
����ÿ��һ������Ҫ˼����0.4���AlphaGo Zero�������������������ڽ��Ŷ���ʱ����������ȫ��ͬ�ģ�����û���˻��F1����ʽ�����ܱ�����һ����
������ô����������ģ�
����������ͼ�������ȸ�ϰһ����ǰ��AlphaGo����ô�����ģ�
������ȥ��AlphaGoÿһ���˼������Ϊ�������������IJ����ǣ�
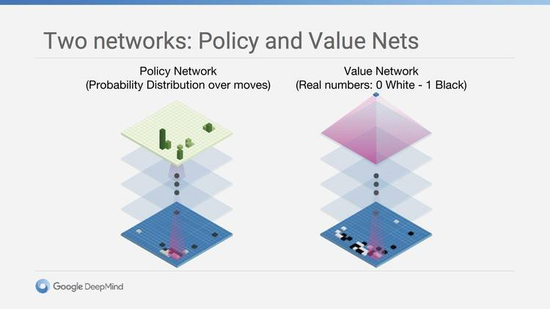
����1����ȡ�����Ϣ��AlphaGo����ݲ������磨policy network��̽���ĸ�λ��ͬʱ�߱���DZ�ڼ�ֵ�߿����ԣ����������������λ�á�������̵ó��Ľ���Ǹ��ʷֲ�����������ÿ��λ�ö��л��ᱻѡ�У���������»���һ���ض�������ӵ�и��ߵĸ��ʡ�
����2��������һ���ó��ĸ��ʷֲ�����ֵ���磨value��network����Ը��ʸߵĵ����ٽ�һ�����жϣ��ó�һ��ֻ������ֵ�Ľ����ÿ������λ��Ҫô���ж�Ϊ�����Լ�Ӯ��Ҫô���ж�Ϊ�ö���Ӯ��
�����ڷ��������ʱ�����ʱ��ģ������б�ϵͳ��Ƶ�������λ�ý���Ϊ AlphaGo ������ѡ���ھ������ڵ�ȫ��̽�������ж�������ӵIJ��ϴ�Ħ��AlphaGo�������㷨���������������֮�ϼ�����������ֱ���жϡ�
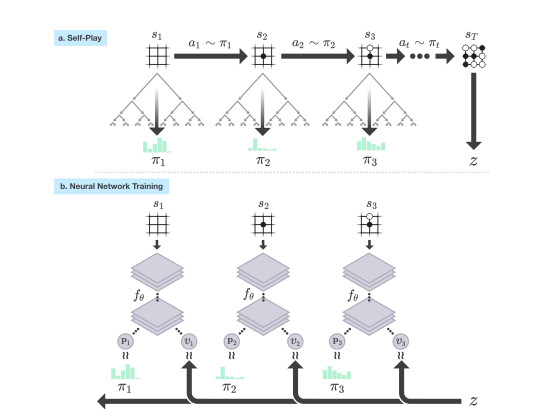
�������µ�AlphaGo������ʱ�в�û�����ԵIJ����������ֵ����ķֽ磬������������ͼ�ֵ�����趨Ϊһ���µ����������f�ȣ�s��= ��p�� v�� ������sΪ����λ�ã�p��������ԭ�����������д������Ӹ��ʣ�v�����������Ӻ��ʤ�ʡ�
����f�ȣ�s��ͬʱ���Լ��Ͷ��ֵ�ʤ�ʽ���Ԥ�⣬��ÿ��λ��s��������f�ȶ������һ�μ��㡣������һ�ζ�ս��ʤ��Ӯ��һ����ʹ�õ�p��vֵ������Ϊ����������f�ȡ�ʹ��ÿһ�ζ�ս���AlphaGo Zero�㷨���ڳ��ſ��ܴ��ڵIJ��ܹ�ʽf�ȣ�s��=���У� z��������
�������ԣ���ʲô�ã�
�����������������ǿ����ʲô�ã���
���������ڽ���������AlphaGo��������ɣ���ȷʵҲ��������ͨ�Թ�Ⱥ�ڵ����ɡ���������壬�����۸��½�ܵ�֮��ȷʵû��ʲô�á����ǣ���Ҫ���ǣ����о���������Χ����һ����Ĺ����У�DeepMind�Ĺ���ʦ���˹������ϲ�������Ҫ��ͻ�ơ�
������Щͻ�ƿ��Թ㷺��Ӧ�õ�����ʵ����������������ȥ��7�·ݣ�DeepMind�ͱ�ʾ�����ȫ���ƶ� AI ʵװ���������ĵĻ�����߿��Դﵽ 15%���õ�������
����Deepmind��Ϊ����һ��AlphaGo Zero�ϵ�ͻ���ܹ����˹�������һЩȱ�����ݻ������쳣�����������õķ�չ������ģ�⵰�����۵��з���ҩ��Ѱ���µĻ��ϲ��ϵȡ�
��������Ҫ���ǣ�ͨ���㷨�����˹����ܵ�Ч�ʣ��ܹ�������ٶ�Ӳ�������ϡ�������������㻹���������˹�������μ����������ĵ����Ļ������Կ�һ�����ֱ�۵ĶԱ�ͼ��
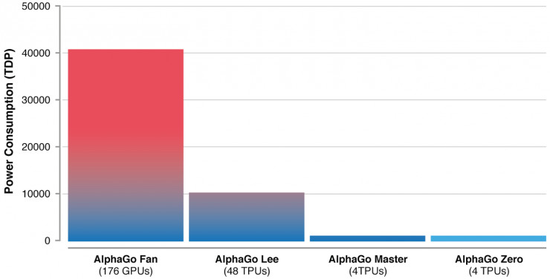
���� AlphaGo ���������ĸ��汾���ܺĶԱȣ���һ���������ϢϢ��ص����ִ�������������ⱳ��ļ�ֵ��
����2017�꣬Google����������2015��ȫ����������ĺĵ��������ʱGoogleһ����õ���Ϊ57��ǧ��ʱ������Ա������ָ��˾��õ�Ĵ�������Աȣ����൱�ڱ���712���˵��õ�����
�����������������ϣ������ǽ�ʡ10%��Ҳ�ܹ��Գɱ��ͻ�����ɾ�Ӱ�졣
����������һ���Աȿ������������˹����ܶ���������ĸı䡣�������90������ˣ�Ӧ�û��ǵ����������Ͽ������Ǹ������������ƻ���������һ���˵�23��Ⱦɫ�����ȫ������
���������ʱ13�꣬���ʳ���10����Ԫ���������й���Ӣ�����ձ��������͵¹�6������20������ѧ���о�������ɵġ������̡������������û���ѧϰ������һ�Ρ������ڴ�ԼΪ���ܣ��ɱ���ԼΪ2�����𡣶�����Intel���������IBM��Google�����ڵ��¿Ƽ���˾��������ͼ��2020���������ֽ���24Сʱ��1000��Ԫ��
������ȫ�����������Ա���Ϊ�����ࡰ���˰�֢������Ҫһ�����������ڰ�֢��Ԥ����ɸ�顢�������Ƕ�֢ҩ����о��������ϣ����᳹�ı����а�֢���������Ʒ�ʽ��
��������ܾ���һȺ��ȵĸ߲���Ҫ����һ������Χ���������������ǧ���������Ϸ�Ͼ���ԭ��ɡ�
����������Դ��PingWest������